 您好,我是Hellos AI,擅长AI编程、分享AI工具资讯等,立志让更多普通人了解AI、学会AI,利用AI找到人生的第二曲线。【n8n教程】n8n Hellos AI 自动化日报工作流深度拆解(一)
您好,我是Hellos AI,擅长AI编程、分享AI工具资讯等,立志让更多普通人了解AI、学会AI,利用AI找到人生的第二曲线。【n8n教程】n8n Hellos AI 自动化日报工作流深度拆解(一)
【n8n教程】n8n Hellos AI 自动化日报工作流深度拆解(二)
【n8n教程】n8n Hellos AI 自动化日报工作流深度拆解(三)
通过前面的步骤我已经把符合条件的那些AI新闻筛选出来了,接着我需要把它们变成适合在小红书、小绿书等媒体平台上发的图文,那么接下来我该怎么做呢?
这里我将给大家详细的介绍生成封面图片的逻辑!
0****1****思路拆解
其实怎么说呢,我开发这个工作流的实际过程不是按照我文章的这个顺序和步骤来的,而是先开发的日报的模板,然后再来开发的工作流。这里暂且不管他,我们一起来看看封面是怎么生成的!
01俯瞰图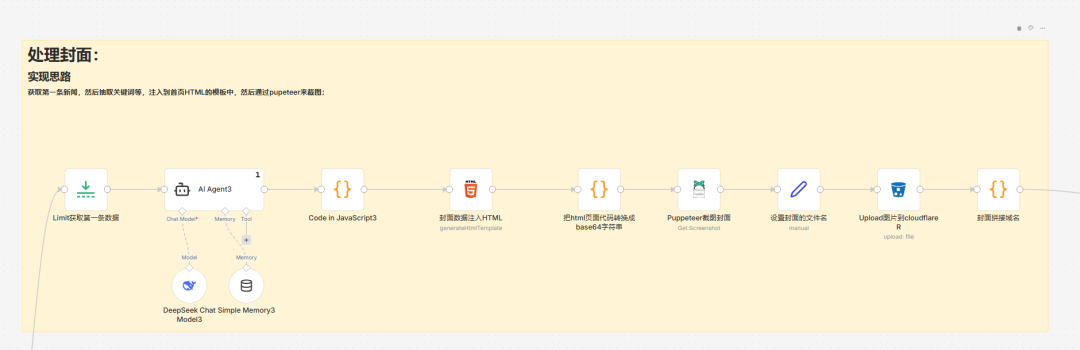
这里总的来说是取第一条新闻,然后对它进行精简、提炼,得到一个非常抓人眼球的标题,接着把这个标题塞到一个html模板中,截图,并上传到CF的S3保存!
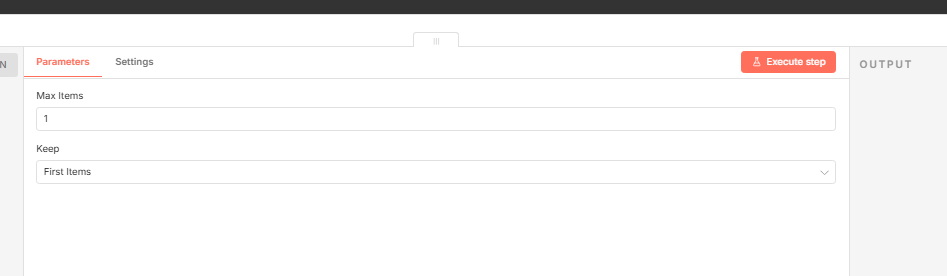
02取第一条
这里为什么我直接取第一条呢?
因为在前面筛选时,我就在系统提示词中做过约束,要求把最有吸引力、最能抓住人眼球的新闻放到了第一个,所以我以它作为封面素材的来源,这个是没有问题的!
这里limit节点就是对一个数组进行截取的功能如下:功能很简单,没啥好说的
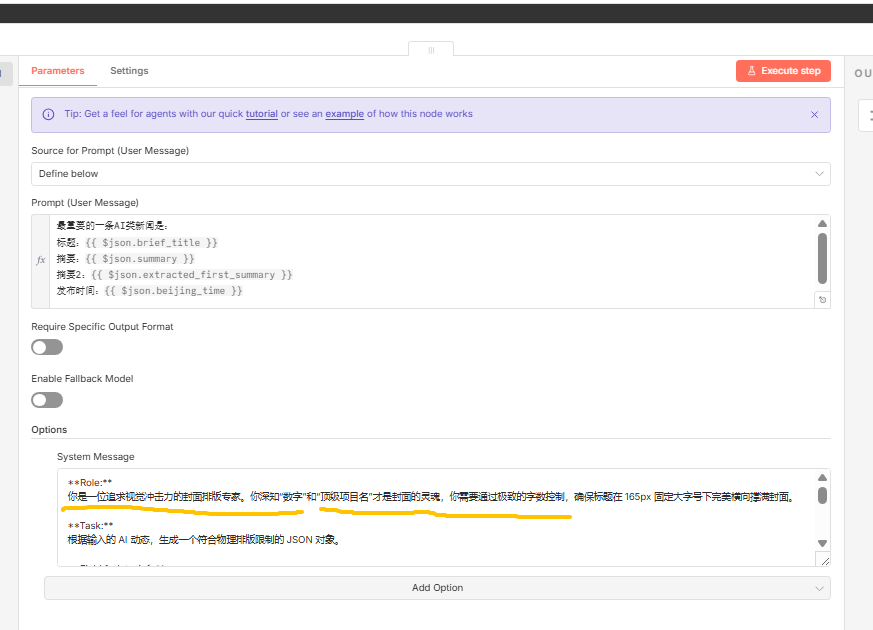
 03生成封面文案
03生成封面文案
这一步是这块逻辑里面最重要的步骤了,这里我取到了最有吸引力的新闻、资讯的所有详情,那么我使用调试过的系统提示词来对这些文字的要点进行提取、精炼,把最能抓人眼球的文字、关键词放到这个封面中,以便追求视觉冲击力,吸引读者的注意!
 04生成模板
04生成模板
这一步也很关键,这里的话就是把提炼好的封面文案塞到一个预先调试好的html模板中,然后然他生成一个静态html页面,这就是我早报封面图的来源!
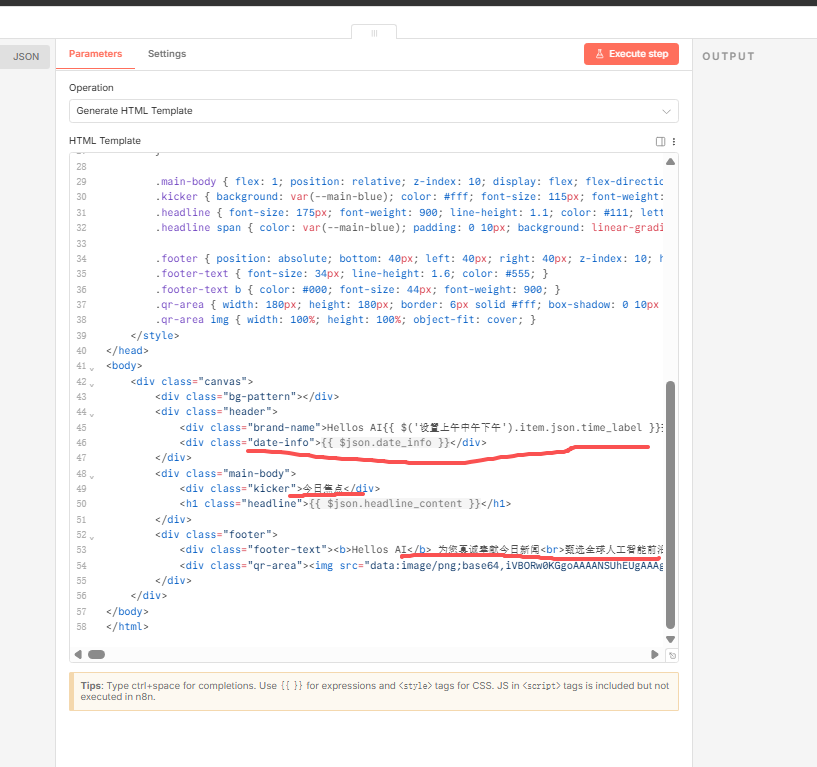
其实大家看到的前面我发的那几个小绿书日报图片都是使用这种html代码来生成的页面,通过固定模板,接着动态注入文案的方式来生成html页面!

例如,上面这个截图就是我调试模板时用到的html!
05生成截图
生成截图这个功能呢应该是这个工作流里面最麻烦的一个技术难点了,它使用到了社区节点,这个还不是麻烦,麻烦的是该社区节点依赖一堆的第三方库,我在这里来来回回折腾了很久,才最终解决这个技术难题,好在最终截图是正常的生成出来了,否则,我得接入第三方付费截图api或者当前工作流可能会胎死腹中!
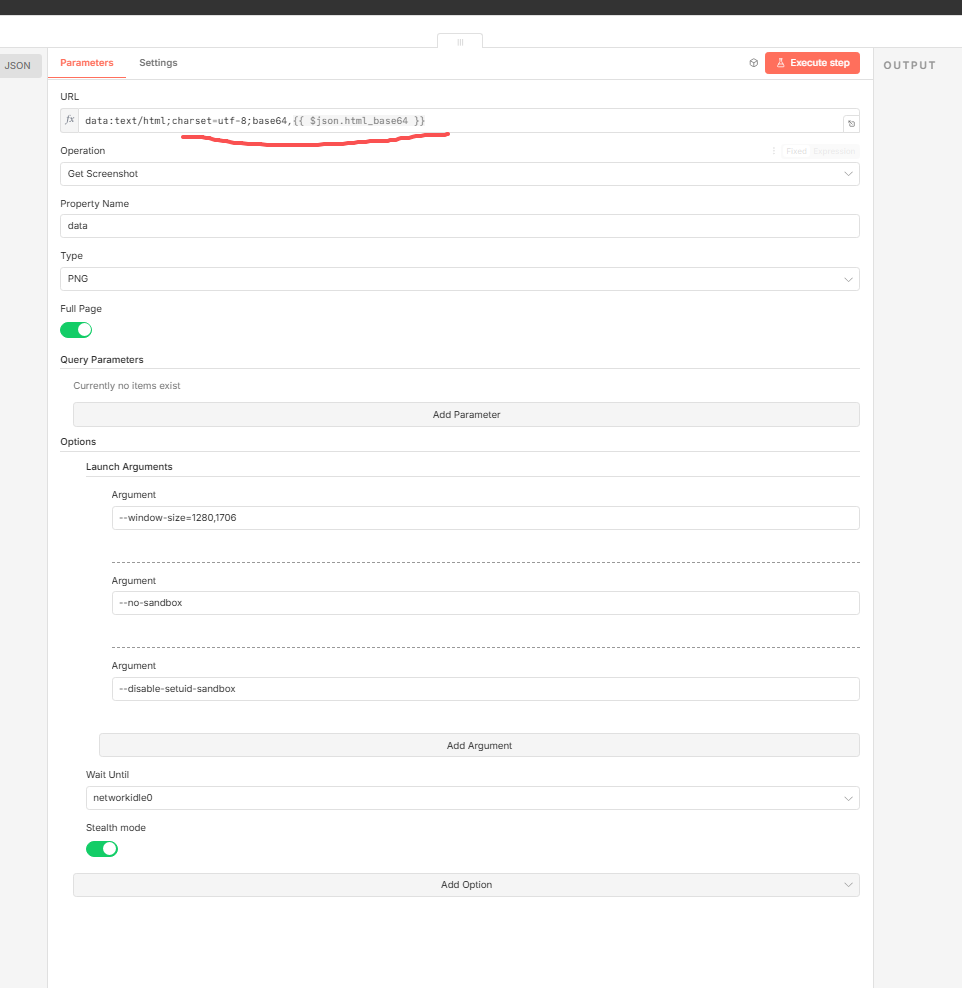
前面生成的html代码在这里是无法直接使用的,所以需要把html代码通过code节点转换成base64编码,然后再这里URL中以base64字符串的形式让这个pupeteer节点来正常的在无头浏览器中正常渲染该页面并且生成截图!
06图片存储
嗯,经过前面pupeteer节点处理后,这个图片算是有了,接着我该怎么样把图片传到我自己的电脑上或者哪个公共的位置呢?
这里就该cloudflare S3出马了,好在我前面做我那个涂色网站时对这个用了一次,所以,这里对这些图片的处理也是轻车熟路,cloudflare的各种access key、id等等都是现成的,通过调试后这个S3节点配置如下:
 07历史执行日志
07历史执行日志
这里,我可以把前面日报的一些执行日志截图给大家看看效果:
 0****2****写在最后
0****2****写在最后
好了,这个难啃的骨头已经在这里给大家拆解过了,接下来敬请关注我后续对新闻详情页的拆解和帖子标题、正文生成的拆解!
另欢迎大家来我的个人博客网站https://hellosai.cc/逛逛!
我不生产工具,我只是好工具的搬运工。
关注杰哥不迷路,每天给你分享不一样的实用好工具。
免责声明:本公众号分享的内容以及软件等来自互联网,仅供大家学习交流,同时请遵守你当地的法律法规,否则造成的一切后果自负,与本公众号无关。如有侵权联删!部分知识难免有时效性,若内容过期失效,请见谅,感谢!
***喜欢这篇干货?如果觉得不错,请帮我一键三连,转发给您的朋友,都是对我最大的鼓励与认可。如果想第一时间收到推送,可以把我的公众号加个星标🌟方便后面我们一起探讨AI或有意思的东西,还能够快速找到我!我们明天见!—END—图 | 来源网络侵删欢迎点赞,在看,转发给我鼓励~👇👇关注我👇👇👇👇扫码加入粉丝群领取福利👇👇