 您好,我是Hellos AI,擅长AI编程、分享AI工具资讯等,立志让更多普通人了解AI、学会AI,利用AI找到人生的第二曲线。
您好,我是Hellos AI,擅长AI编程、分享AI工具资讯等,立志让更多普通人了解AI、学会AI,利用AI找到人生的第二曲线。
今天给大家介绍我搭建的一个简单的工作流,它可以监控google drive文件夹内的文件动态,并且根据文件内容来生成指定风格、过程、步骤的文章!
这里,我把它分享给大家!
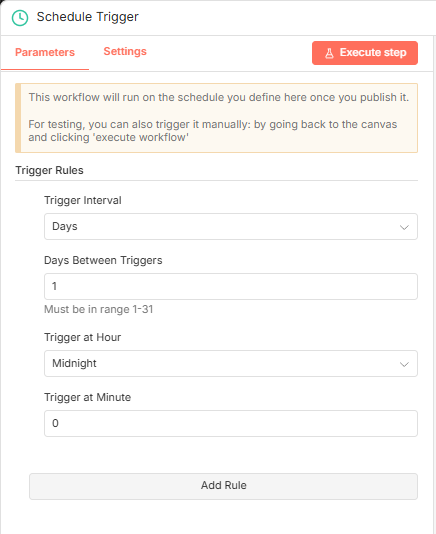
0****1****思路01****细节拆分
这这个地方的话从我这里介绍的来看,它应该包括像:监控文件夹底下的动态、生成文章,那么细细的进行拆分它还会有如下的一些细节和逻辑:
1.我需要指定一个google drive文件夹,对它进行监控;
2.我需要有一个位置可以存储已处理过的文件列表;
3.我需要有生成文章的访问链接;
4.我需要对已处理的文件进行转移,避免重复;
02总体设计
既然这些细节我都考虑到了,那么接下来我需要从整体上对这些进行设计和规划,如:
a. google drive:主要用来存储文件,如:
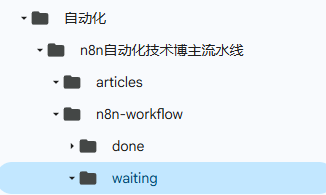
waiting:他是文件夹,用来存储待处理文件;
done:用来存储已处理文件;
articles:用来存储生成的文章;
b.google sheet:主要用来记录这些文件名称、id、创建时间、状态等等;

好了,既然数据存储和文件夹等已经确定下来,那接下来就可以正式开始搭建了!
0****2****搭建子工作流1
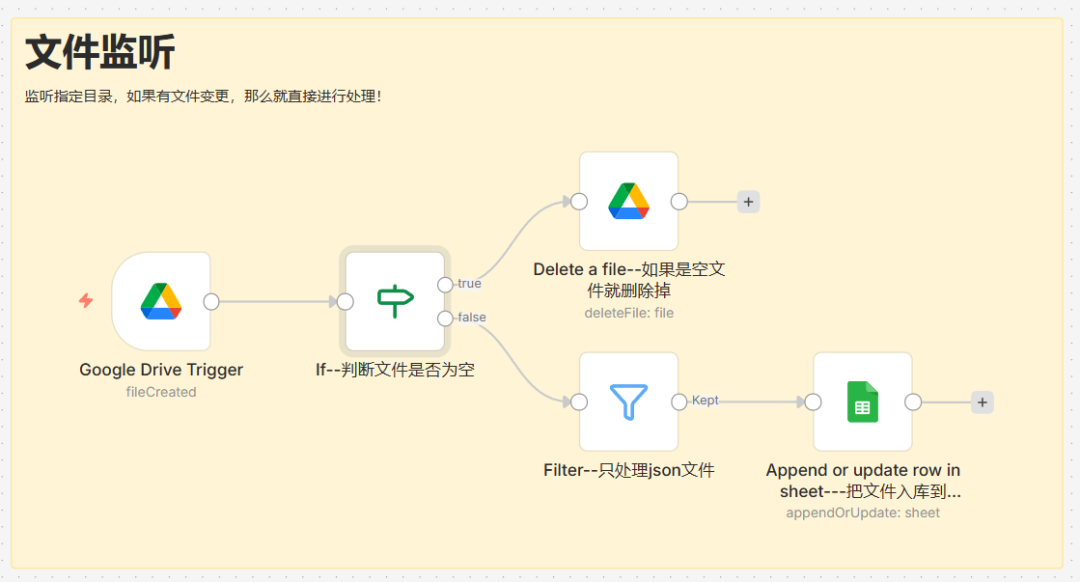
我的思路:这里我需要有一个工作流可以监控google drive指定文件夹的动态,然后把该文件相关的数据保存到google sheet中,该数据状态为"待处理";
该工作流的俯瞰图如下:
 01触发节点
01触发节点
这里触发节点的选择,我们可以选择定时任务触发器节点,也可以选择google drive trigger节点,这里我选择的是google drive trigger节点,我觉得它应该会更好一点,毕竟我的文件在google drive,用它也算是跟它对口!
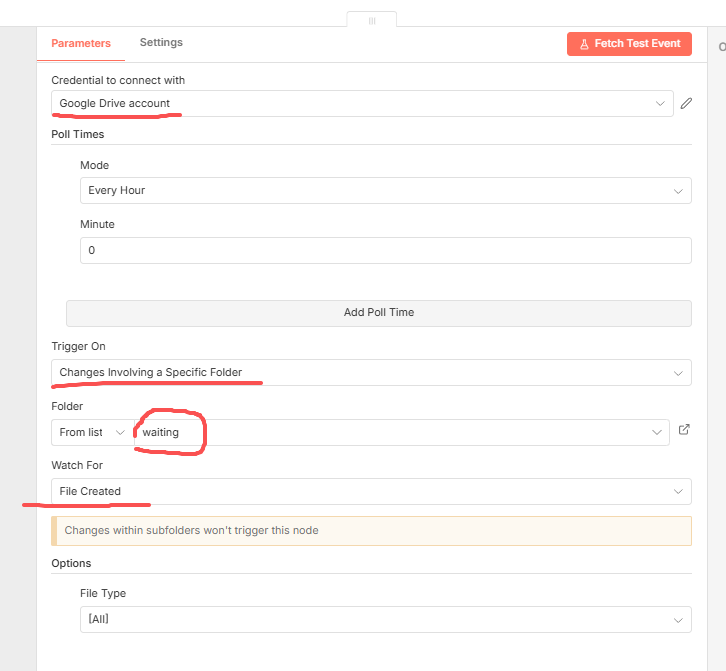
这里大家需要注意:waiting--这个文件夹就是前面我创建的文件夹,file created--这里监听文件创建事件(就是watiging文件夹底下有文件上传,那么就会触发)
02if节点
前面节点触发后,我需要判断当前文件是否是我期望的文件呢?因为一般来说,你可能会把空文件或者非目标格式文件上传到google drive,所以这里对文件size进行判断,如:
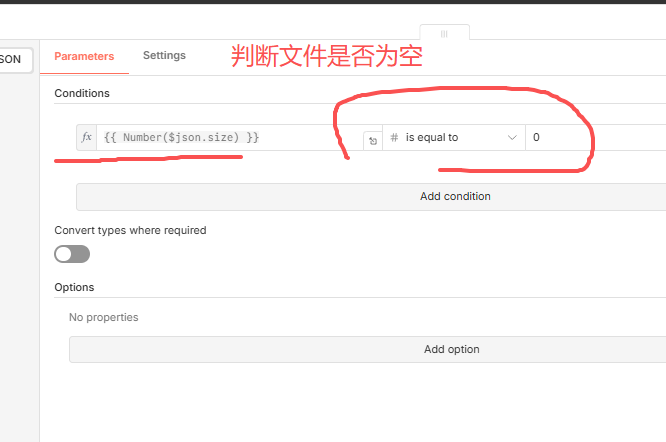
如果文件是空,那么我删除它!
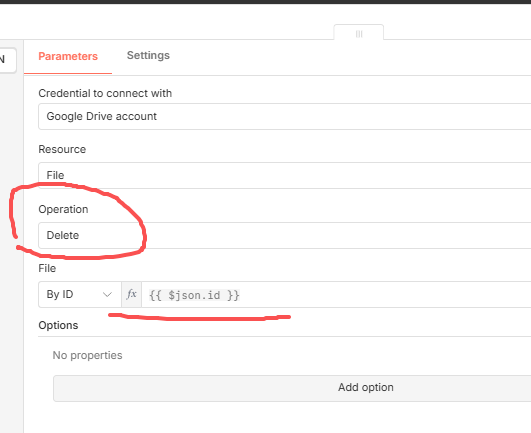
所以,这个删除逻辑这里配置delete操作,然后因为前面的触发器可以返回文件id之类的,这里就直接用id来删除空文件;
03filter节点
那一般用户还可能上传了如txt文件、pdf文件等,但是我想处理的是json文件,所以这里可以对它进行过滤,如:
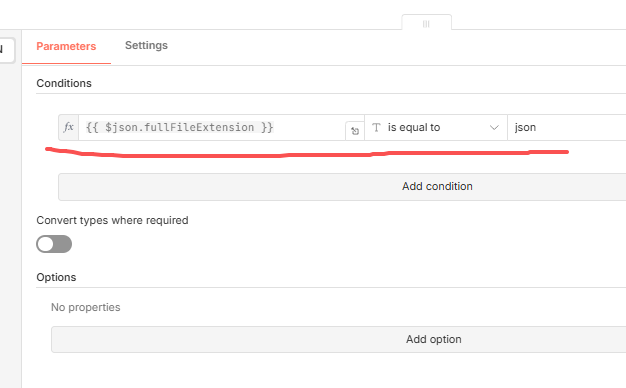
这里我通过文件后缀名来过滤,把json文件都筛选出来!
04google sheet节点
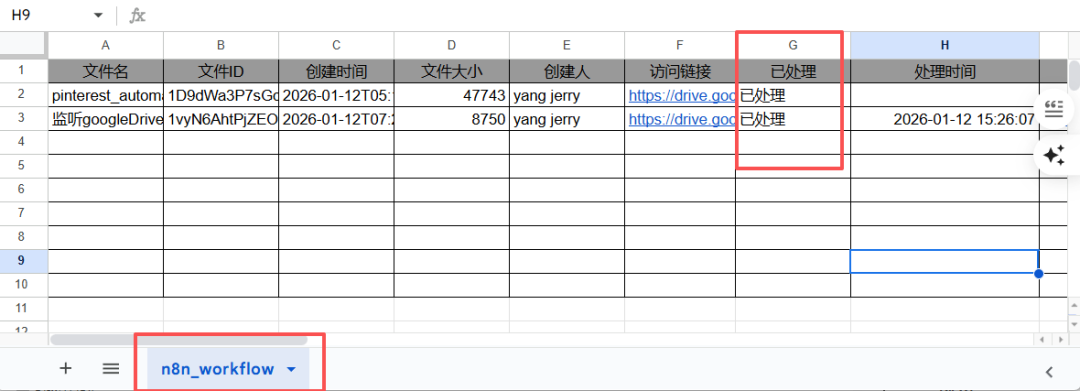
既然文件等都筛选出来了,那么接下来就可以对它进行入库操作了,我这里说的入库是把该文件的关键信息保存到google sheet中,如:
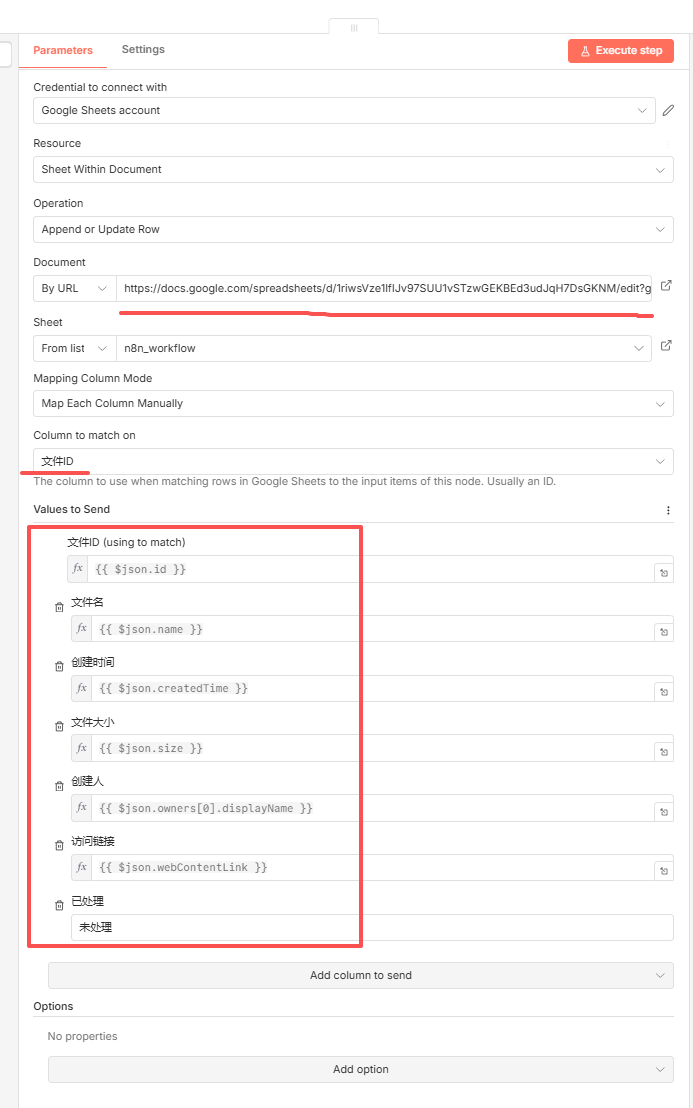
因为一般来说google drive对每个文件都会有它的编号,所以使用文件ID来对不同文件进行区分是比较科学的!所以主键采用"文件ID",这里我需要保存文件ID、文件名、创建时间、文件大小、创建人、访问链接、状态;
好了,当我把文件扔到waiting文件夹后该工作流会自动执行,并且把数据保存到google sheet中!
0****3****搭建子工作流2
我的思路:既然是用它来生成文章,那么每天执行一次,每次取一条数据然后生成文章,接着把文章保存到google drive,最后更新这条数据的状态,这就可以了!
该子工作流俯瞰图如下:
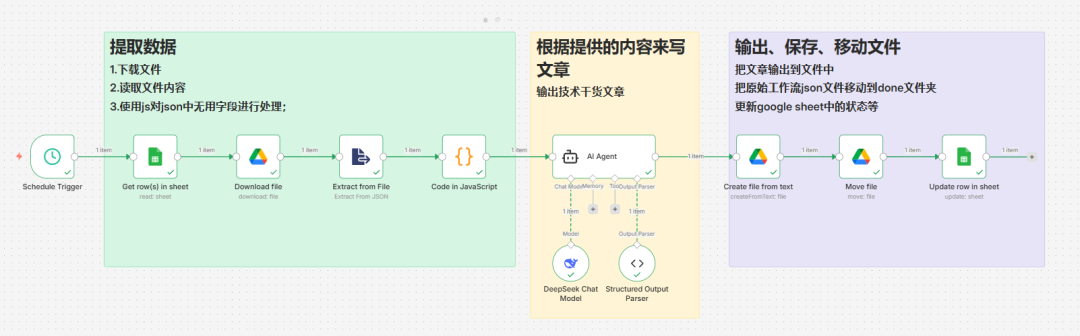 01触发节点
01触发节点
因为在我的设计思路中每天需要它生成一篇文章,那么就使用定时任务触发节点就很适合了!
 02google sheet节点
02google sheet节点
既然工作流开始执行了,那么首先我需要获取到一条数据,这里就还是添加一个google sheet节点,如:
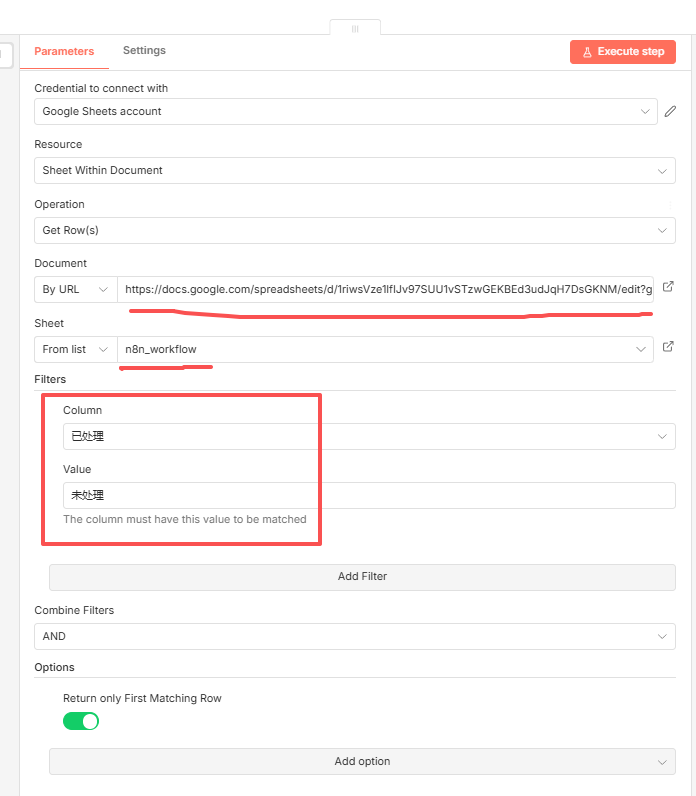
这里上面是google sheet的地址,底下是这个tab的名字,如:
就是查找n8n_workflow这个sheet中状态为"未处理"的那些数据!然后底下还开启了"Return only first Matching row"就是拿首条数据!
04下载文件
既然我已经拿到了文件信息,那么接下来我需要获得该文件内容,还是通过文件ID来获得,如:
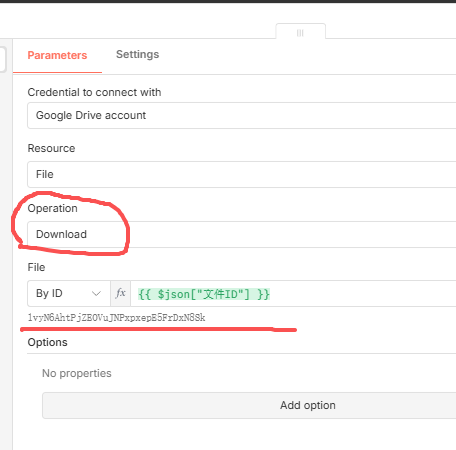
这里通过这个文件ID,就可以获得一个文件对象(它还没有保存到磁盘中,只不过是确实下载到了一个文件)!
05提取内容
这里,我需要把我上传的文件的详情内容提取出来,所以这里就需要添加一个extract from file节点,如:
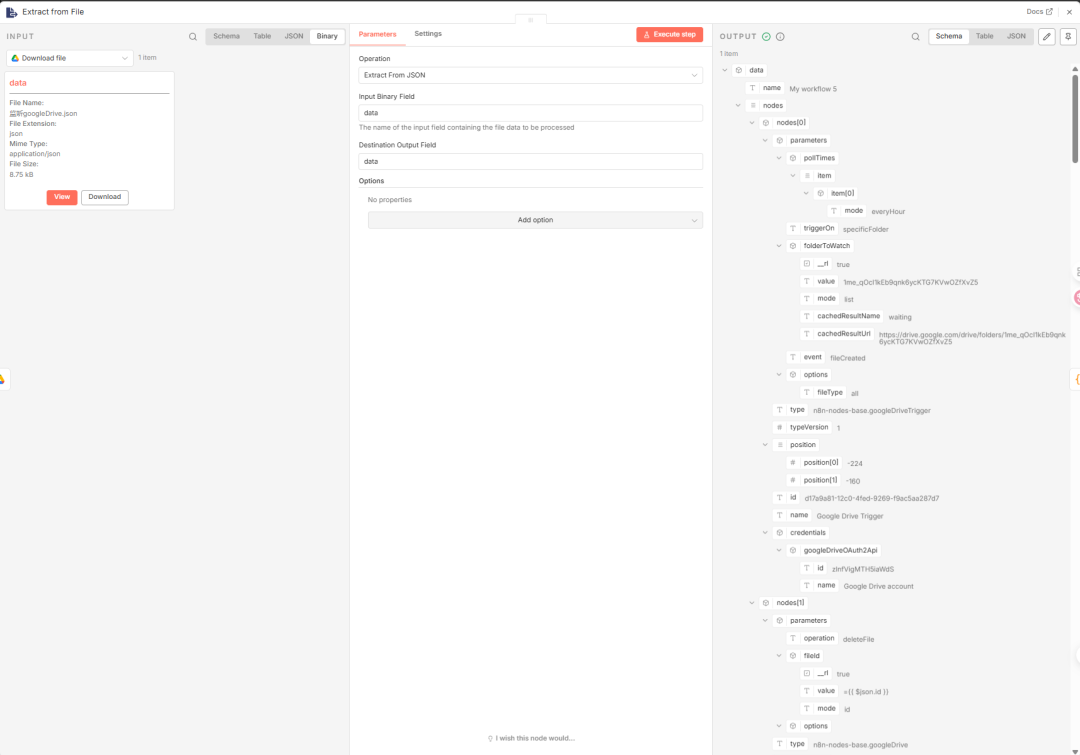 06瘦身
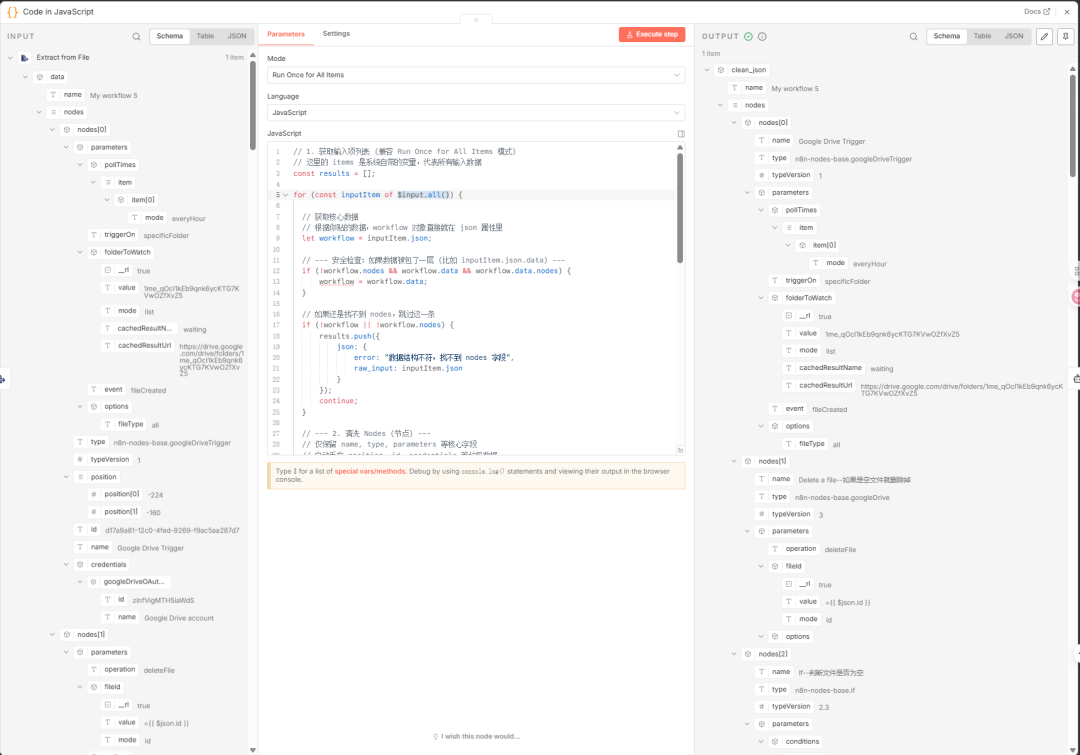
06瘦身
因为原始的n8n工作流json文件中包含大量的像坐标等信息,它们基本上对AI理解该工作流的内容毫无意义,所以这里我通过一个code节点把这个json中这些数据都剔除掉,以便节省AI的token消耗;
 07AI Agent节点
07AI Agent节点
在code节点瘦身后,我们就可以把这些json代码都交给AI来理解并且让它给我生成文章了,我要添加一个ai agent节点,然后通过用户提示词、系统提示词来对输入数据进行处理,最后让AI输出固定格式的json对象:
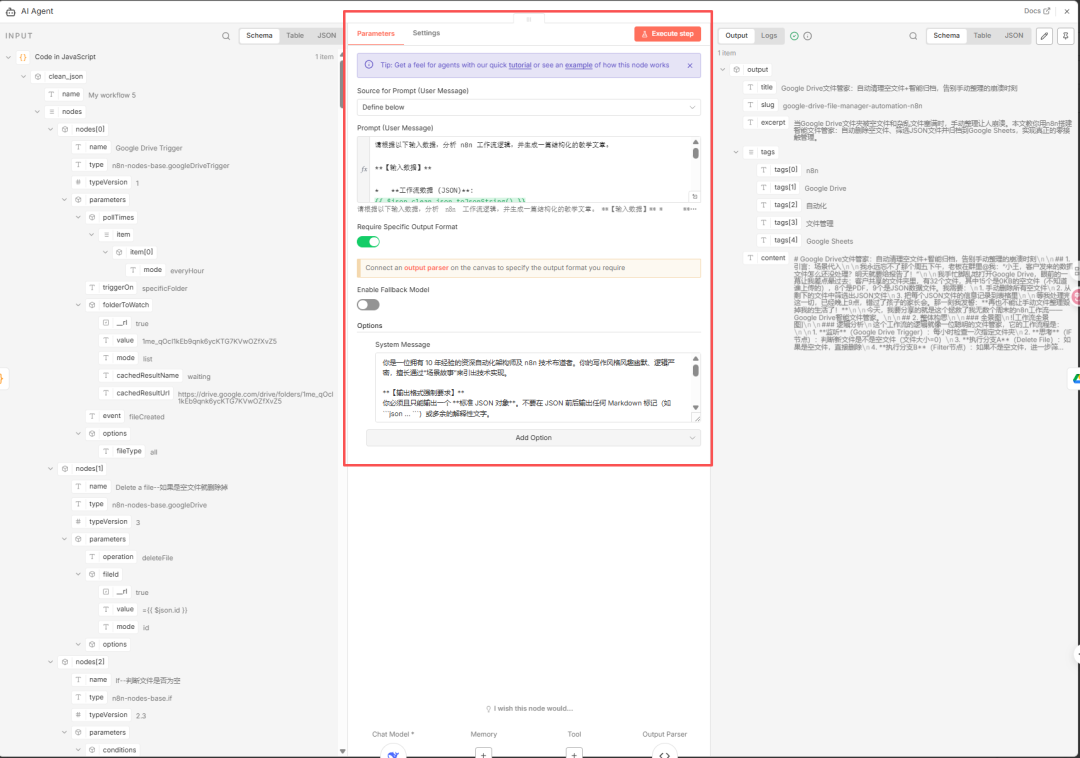
上面截图中右侧那些就是AI生成的内容了!
08保存文章节点
然后就到了我们要保存文章的步骤了,我需要把AI Agent的结果写入到文章中,如:
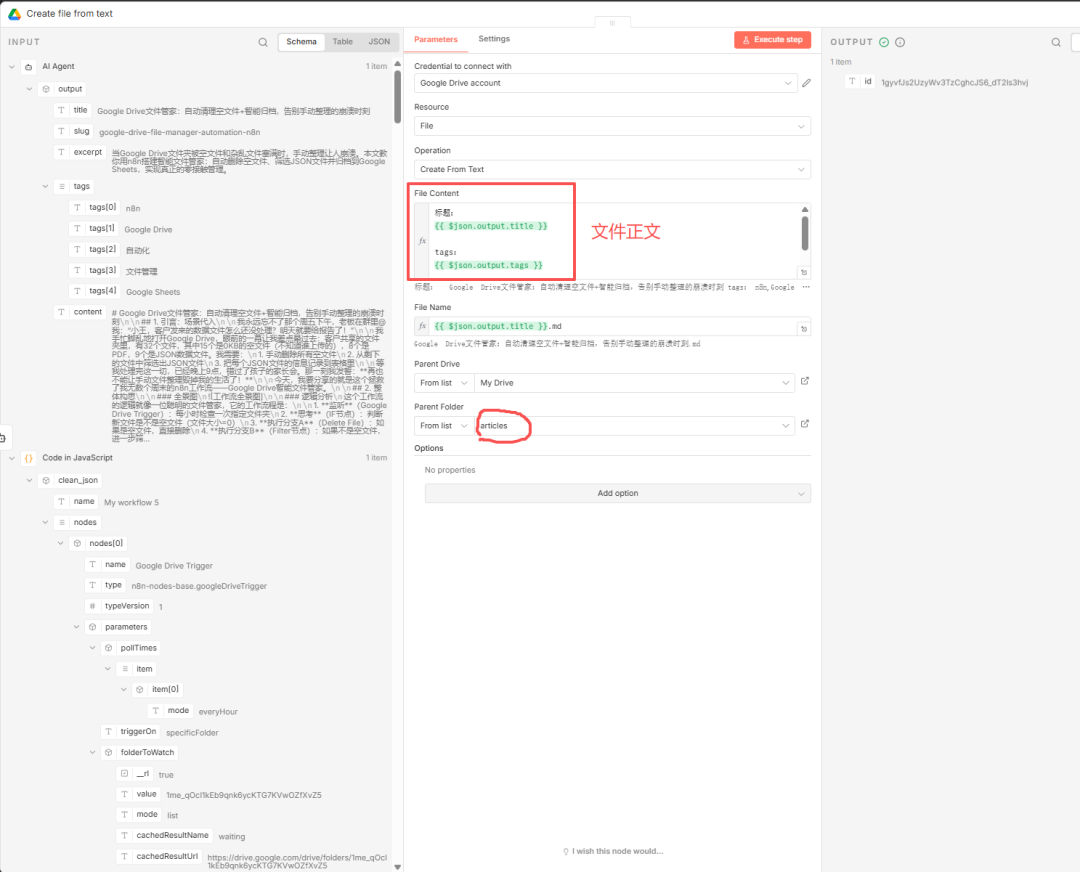
保存文章后,这里输出一个id,他就是这个文件的唯一标识!
09google drive节点
既然这个json文件我们已经处理完毕了,那么接下来,我们可以把处理过后的文件移动到归档文件夹done下,所以这里就添加了一个google drive节点:
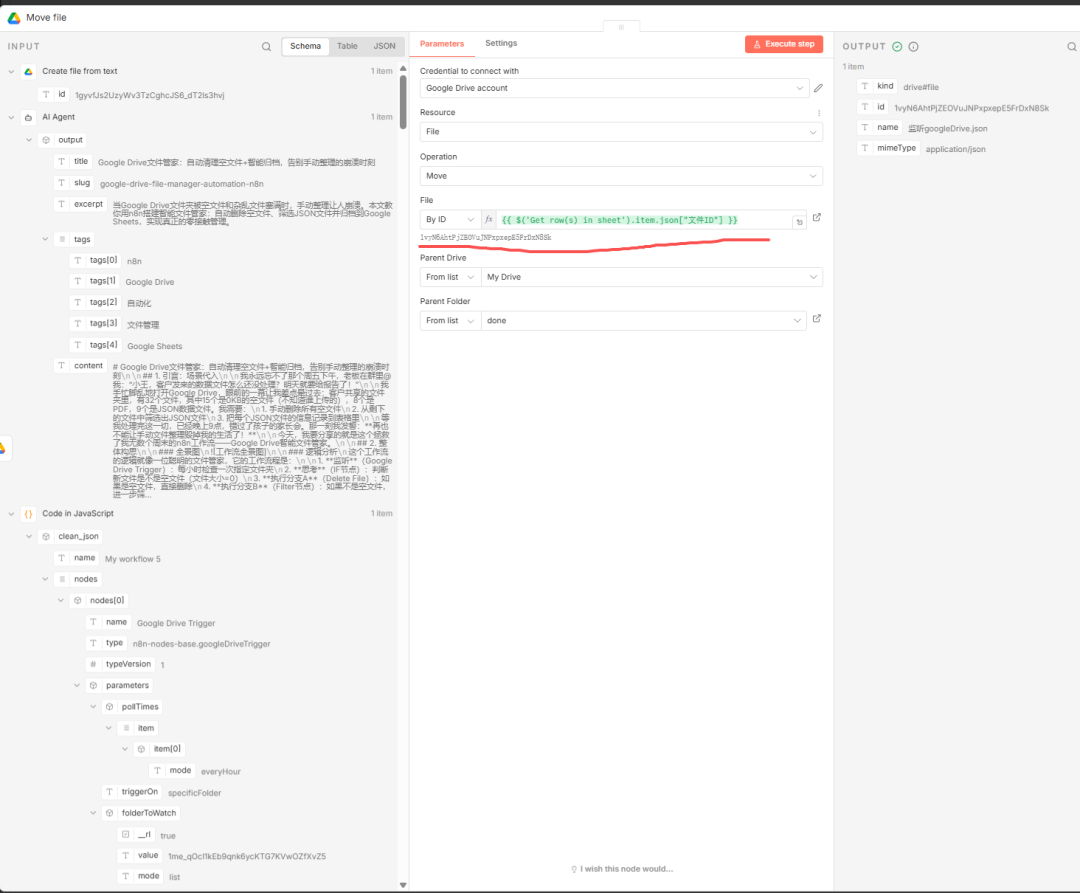 10****google sheet节点
10****google sheet节点
在文件移动后,当前处理的这条数据呢需要进行状态变更,当然最重要的还有文章链接的存储,所以这里需要对这条数据进行update操作,如:
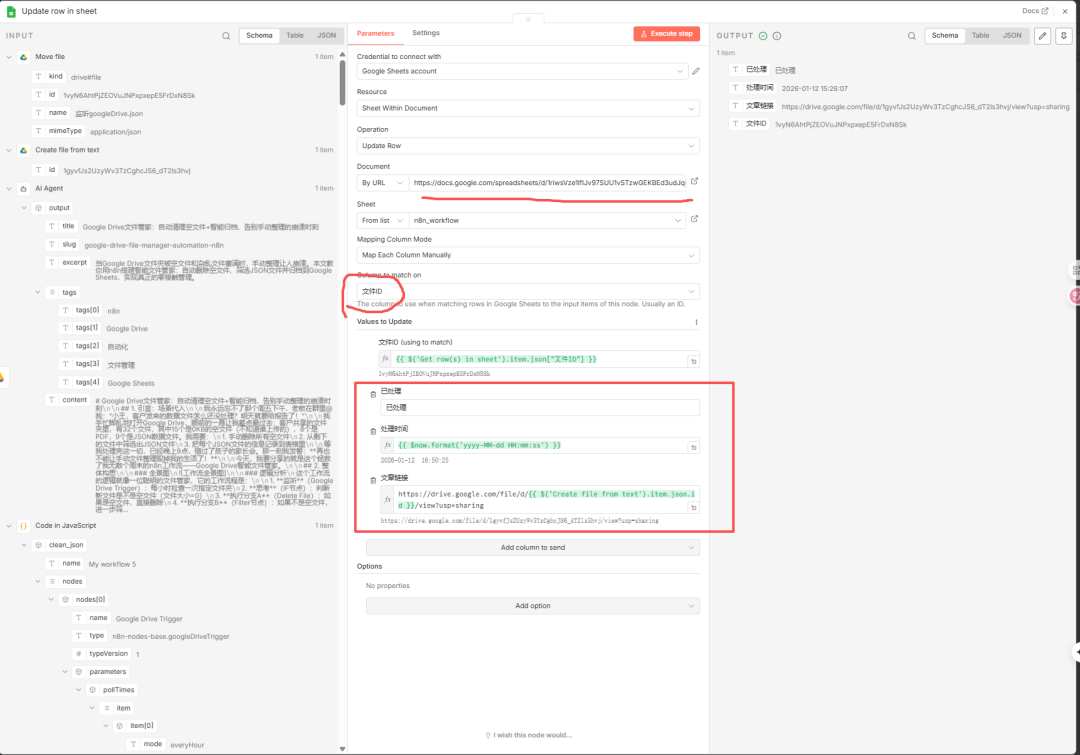
注意:这里我仍然以该条数据的"文件ID"作为主键进行更新,这里对像状态、更新时间、文章链接进行更新(原始状态下更新时间、文章链接都是空)
好了在该条数据的状态已经更新后,这个工作流的数据流转就闭环了!结束了!
0****4****写在最后
好了,这个工作流的搭建就到这里了!
其实呢对于这些工作流的搭建也都不复杂,总体上来说就是,先要明确我要做什么!我有哪些基础条件(例如,我有google drive账号、我已经注册了飞书、我有哪个AI的token等),我该如何来存储这些数据!这些数据一步一步的该怎么处理,把这些过程、步骤捋清楚,那么这个工作流就能很快搭建出来了!
另欢迎大家来我的个人博客网站https://hellosai.cc/逛逛!***喜欢这篇干货?如果觉得不错,请帮我一键三连,转发给您的朋友,都是对我最大的鼓励与认可。如果想第一时间收到推送,可以把我的公众号加个星标🌟方便后面我们一起探讨AI或有意思的东西,还能够快速找到我!我们明天见!—END—图 | 来源网络侵删欢迎点赞,在看,转发给我鼓励~👇👇关注我👇👇👇👇扫码加入粉丝群领取福利👇👇